Scene 5: Avatar
In the Scene 1: Stock Photo, the method of img2img is introduced. This method not only solves the problems in Stock Photo but also works well for multiple scenarios.
This chapter will focus on introducing prompts generated using this method for creating avatars. Starting from this chapter, we will gradually enrich our prompt structure to make it more complete.
Notes:
Before introducing the application of img2img, I want to emphasize that:
- Do not upload your own photos in the Discord Midjourney public group! Your photos will be visible to everyone in the public group. It is recommended to use Midjourney Bot.
- In addition, non-pro paying members' generated images can be seen by other members. However, you can delete the generated images after creating your avatar. If you are unsure how to use Bot or delete photos, please refer to Basic Operations.
- I won't go into too much detail about how to operate img2img here. If you're still unclear about it, please refer to Basic Operations and Stock Photo chapters.
3D Cartoon Avatar
The first thing to share is cartoon avatars. First of all, I want to emphasize that:
- I have basically read and tried out the tutorials for generating avatars, and also communicated with people in the Midjourney community. My understanding is that with the current ability of V5, no matter how you adjust the prompt, it is basically luck-based to generate an image that looks very similar to the original using img2img method. Even if you use the seven techniques introduced earlier, it only increases probability. If you have a method that can make avatars look very similar, feel free to share it with me
- During your learning process, if you find that the generated image does not look like the original one, don't be discouraged. This is normal.
- You can use my shared method to generate a cartoon avatar with some resemblance to the original image. Note that it will definitely not be exactly like the original.
Add the link of your original image in prompt (it's recommended to use ID photos or photos with simple backgrounds as they increase success rate), then design a prompt using framework mentioned earlier:
| prompt | explain | |
|---|---|---|
| Type | Portraits / Avatar | / |
| Main Body | smiling cute boy, undercut hairstyle | This can be optional. You can leave this description blank and only fill in the other prompts. If the generated image doesn't look like you, then you can add some words here to describe your avatar, such as gender, appearance, hairstyle, accessories (such as glasses, earrings), expression etc. Please note that it is better to input distinctive features for better results. |
| Environment | white background | I have kept the white background of the ID photo here, you can add some actual scene backgrounds, such as a restaurant or something similar. |
| Composition | null | Because we pre-passed the picture, the picture is an ID photo, so do not fill |
| Lens | soft focus | Soft focus refers to the use of a soft focus lens in photography, which produces an effect that is both clear and soft. It is commonly used when shooting portraits, and I added this feature in prompt to make photos appear softer. You can also choose not to use it. |
| Style | 3d render,Pixar style | Because the goal is to generate 3D photos, a 3D render has been added here, as well as my favorite Pixar style. |
| Parameters | -- iw 2 | iw is a text and img weight parameter. The larger the value, the more similar it is to the original image. For an introduction to this value, please refer to the advanced parameters section. |
Finally, there are three more tips:
- If the generated photo doesn't look like the preset photo, you can choose one of the four images that looks more similar and then click V (Variation) to let the model continue generating. Then pick another image that looks a bit closer and continue generating new photos until you get one that looks more similar.
- I think this is amazing. If you've tried both of the previous methods and your generated image still doesn't look like the original, add "wear glasses" to your prompt. It's really amazing - whenever I add "wear glasses", it works very well. If your original picture has glasses on, try adding "--no glasses" as a parameter and you'll get an even less similar image.
- Lastly, use an additional parameter which will be explained in tip eight.
Tip 7: Using Multiple Parameters Simultaneously
When using the img2img method to generate avatars, I found that the problem was that "the weight of text is higher than that of images", which resulted in generated images not resembling the original image. The iw parameter can only increase the weight of images up to 2 in V5, so I wondered if it was possible to further reduce the weight of text.
Then I tried using the s parameter and found that it improved a lot.
If the generated image still doesn't look like what you want, you can add another parameter --s 200 on top of --iw 2.
Note that when using two parameters at once, there should be no comma between them. After adding s parameter, I found out that it really improved a lot. Personally, I guess combining s and iw will weaken the weight of text.
S controls how stylized your generated image is. Simply put, lower values are more consistent with your text prompt description while higher values have stronger artistic effects but weaker correlation with your text prompt. So if your generated image still doesn't look right, try increasing this value - for example adjusting it to 500.
Through this case study, I want to tell everyone that using multiple parameters together may form a synergy effect and further enhance model capabilities. In future updates with new parameters available,it's worth considering whether they could be used together as well?
Anime style avatar
As with the 3D cartoon avatar, the main modifications are in the style of the image:
| prompt | explain | |
|---|---|---|
| Type | Portraits / Avatar | Continue using the same description. |
| Main Body | smiling cute boy, undercut hairstyle | Continue using the same description. |
| Background | white background | Continue using the same description. |
| Composition | null | Continue using the same description. |
| Lens | null | Because it's a comic style, we won't add soft focus lens. |
| Style | anime, Studio Ghibli | The goal is to create an anime-style avatar, so here we added the word 'anime' and then incorporated the Studio Ghibli style. |
| Parameters | -- iw 2 —s 500 | Note that when two parameters are used at the same time, there should be no comma in between. |
Cyberpunk avatar
This is one of my favorite styles, and it is also just a matter of changing the style and background
| prompt | explain | |
|---|---|---|
| Main Body | cyberpunk robot face, holographic VR glasses, holographic cyberpunk clothing | With added facial embellishments, as well as wearing VR goggles and cyberpunk-style clothing. |
| Background | neon-lit cityscape background | In order to make the picture more like cyberpunk, a neon-lit city background was added to make it look more cyber. |
| Style | Cyberpunk, by Josan Gonzalez | Added a cyberpunk style, as well as my favorite cyberpunk artist Josan Gonzalez. |
Tip 8: Use Seed Parameters to Modify Images Again
Note: Personally, I think this technique has great potential in the future, but currently Midjourney's implementation is still relatively average and the effect cannot be guaranteed.
The official community help documentation also mentions that this feature is very unstable in V5.
For more details, you can refer to the Midjourney Official FAQ chapter that I have compiled.
You may encounter a scenario like this:
- You input a prompt and the machine generates four images.
- After looking at the four photos, you find one of them okay but not satisfied with the rest. Then you modify the prompt and generate some more using the machine.
- But you are not satisfied with any of these generated photos and wonder why it is so.
- Then why not make modifications on top of the first generated image?
Based on one generation result for secondary prompt modification should theoretically work.
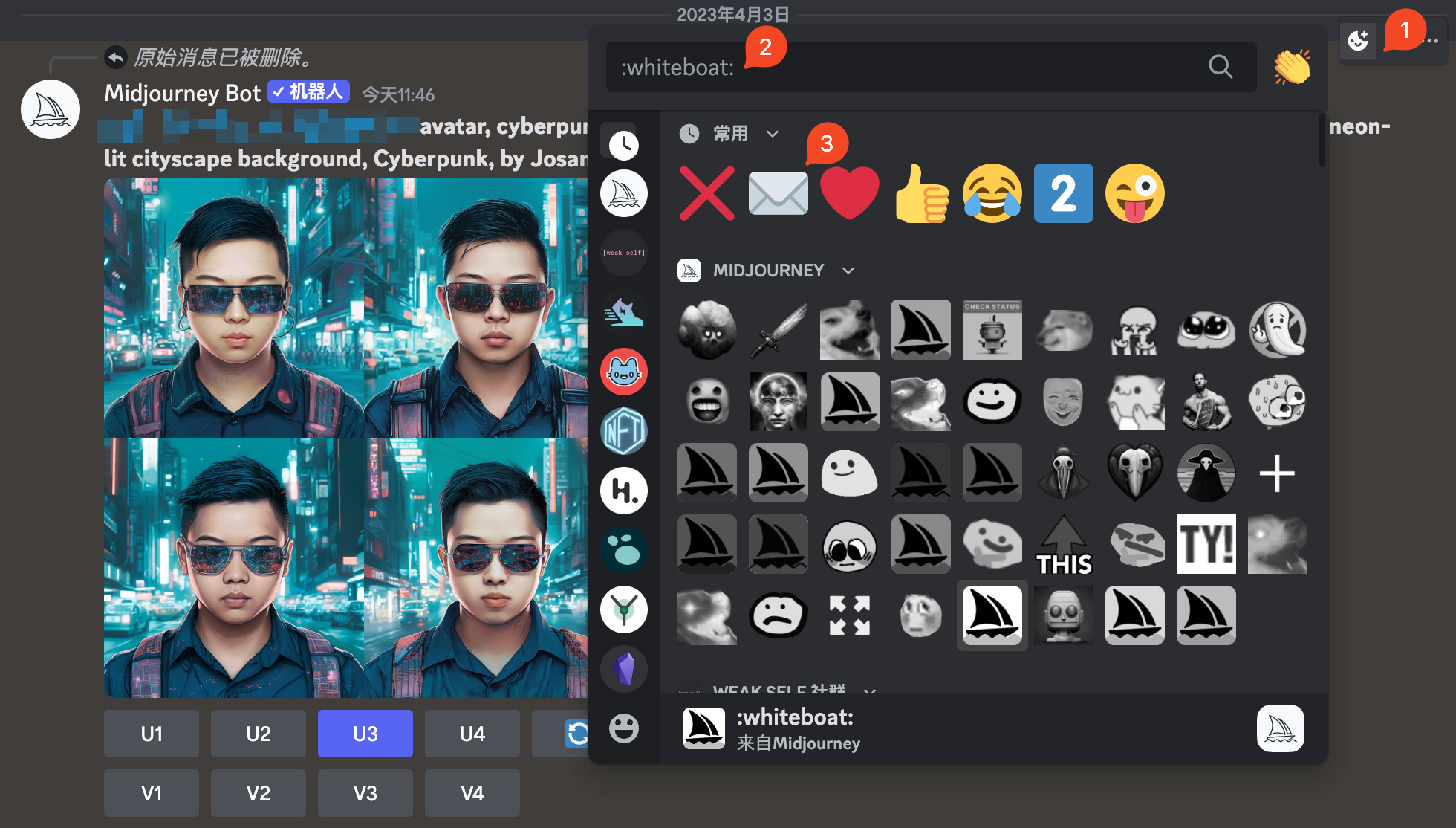
Taking Cyberpunk avatars as an example, I first used above-mentioned prompts to generate four images.
Then click on emoji button (Figure 1) at upper right corner of message box, type "envelope" in input box (Figure 2), then click envelope emoji (Figure 3). Bot will send seed number to you.
I then modified the prompt for the cyberpunk avatar above to change the background to China Town, at which point it is important to note that
The new prompt doesn't just change the background, you need to bring in all the previous prompts. The prompt only changes the background part. Finally, bring the seed parameter. Here is my example:
Original prompt:
{img url} avatar, cyberpunk robot face, holographic VR glasses,holographic cyberpunk clothing, neon-lit cityscape background, Cyberpunk, by Josan Gonzalez --s 500 --iw 1
New prompt (the seed code is just an example, you have to fill in your own seed):
{img url} avatar, cyberpunk robot face, holographic VR glasses,holographic cyberpunk clothing, China Town background, Cyberpunk, by Josan Gonzalez --s 500 --iw 1 --seed 758242567
Here are the generated results (the left image is the original image, the right image is generated after using seed), you can see that the background did change, but the appearance of people also changed a little 😂
The effect is not very good, but I think it is worth exploring, so as to improve the success rate of progressive optimization: the

Tip 9: The mysterious blend feature
This trick, to be honest, I don't think I can call it a trick, but it's a very important feature for Midjourney, so I'll highlight it here.
It's very simple to use, just type /blend in the Discord input box and click on this menu:
After that your input box will look like this:
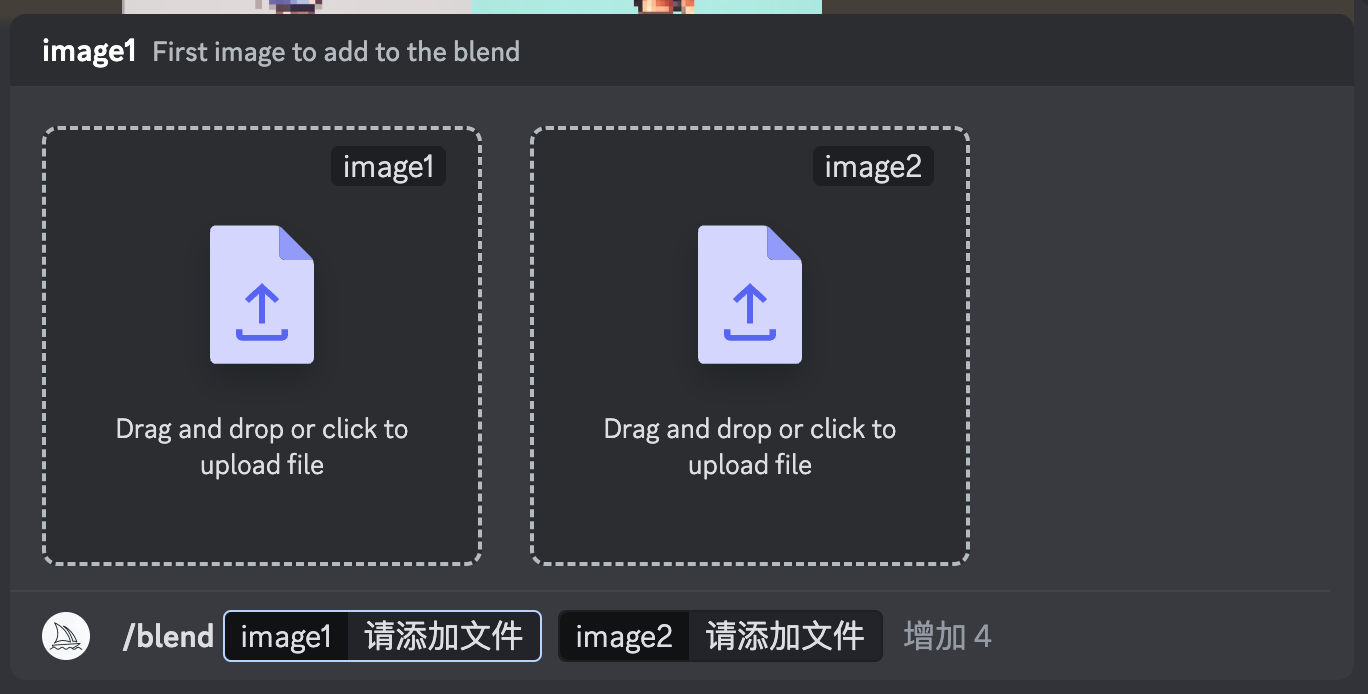
Then you can click on these two boxes, select the photos on your computer after adding them, shout out "use fusion card" (not really), and then press enter.
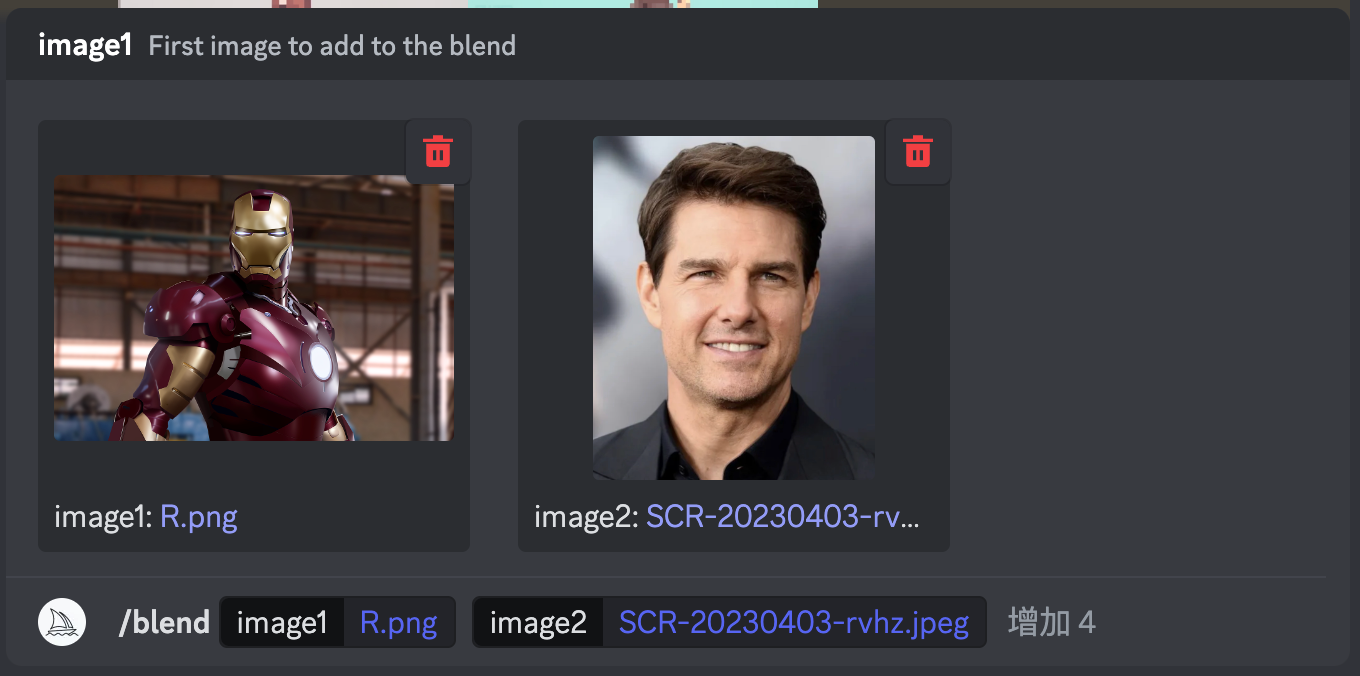
Then Midjourney will generate such awesome results, with Iron Man fused on the left and Buzz Lightyear fused on the right:

This feature is very unstable and can only achieve the above effects under multiple unknown conditions.
I originally planned to use this method to generate avatars, but I found that if I use my own photos to fuse with other styles of photos, the effect is not very good. So far, the best results have been achieved with celebrity avatars. My feeling is that Midjourney has fed a lot of celebrity avatars to the model, so these fusion effects are very good.
But I think it's really suitable for making avatars. By fusing your own avatar with another image, you can generate a nice picture quickly and easily. Unfortunately, this feature doesn't seem to be easy to use yet.
Of course, this feature is not limited to just avatars; there are many other scenarios where it can be used effectively which will be